Understanding XML and Xpath
Updated:
Understanding XML
XML stands for eXtensible Markup Language. XML was designed to store and transport data.
It is a textual data format with strong support via Unicode for different human languages. The design of XML focuses on documents, the language is widely used for the representation of arbitrary data structures such as those used in web services. Several schema systems exist to aid in the definition of XML-based languages, while programmers have developed many application programming interfaces (APIs) to aid the processing of XML data.
-
There are different types of nodes in XML. For Further details, refer the following link.
-
XML document must conform to a specific set of syntactical rules. For Further details, refer the following link.
-
XML document should be well-defined and valid. For Further details, refer the following link.
Understanding XPATH
XPath stands for XML Path Language which is a query language for selecting nodes from an XML document.
In addition, XPath may be used to compute values (e.g., strings, numbers, or Boolean values) from the content of an XML document.
Features of XPATH
-
Structure Definitions : XPath is used to characterize the parts of an XML Document i.e. element, attributes, text, namespace, processing-instruction, comment, and document nodes.
-
XPATH Path Expressions : XPATH expressions targets specific nodes or values in an XML document. The XPATH expression syntax address the nodes in the hierarchical tree nature of an XML document.
-
XPATH Standard Functions : XPath provides a library of standard functions to manipulate string values, numeric values, date and time comparison, node and QName manipulation, sequence manipulation, Boolean values etc.
-
XPath is a core component of XSLT : XPath is one of the major elements in XSLT standard and is a must have knowledge in order to work with XSLT documents.
-
Path is W3C recommendation : XPath is an official recommendation of the World Wide Web Consortium (W3C). It defines a language to find information in an XML file.
-
The XPath language is build on a tree representation of the XML document, and provides the ability to navigate around the tree, selecting nodes by a variety of criteria.
-
XPath has been adopted by a
number of XML processing libraries and tools, many of which also offer CSS Selectors, another W3C standard, as a simpler alternative to XPath. - PATH expression result in object which can be of following types :
- Node-Set(Collection of nodes)
- String
- Boolean
- Number(Double in .NET)
- XPath defines seven types of nodes which can be the output of execution of the XPath expression.
- Root - Root element of the XML Document.
- Element - Element Node.
- Text - Text of an element Node.
- Attribute - Attribute of an element node.
- Comment - Comments on the XML Document .
- Processing Instruction - Processing instructions (PIs) allow documents to contain instructions for applications. PIs are not part of the character data of the document but MUST be passed through to the application. Syntax for the PI is <?target instructions?>.
- Namespace - Namespace declarations make the elements of an XML document distinguishable and addressable when using an instance of an XPATH. Namespace prefixes provide a brief syntax for addressing namespaces.
- Evaluation of an XPATH expression is done on the basis of the context of the
expression. An expression consist of -
- a node (called context node)
- Variable binding
- Two variables (one context position and another context size)
- Function binding
- Collection of namespaces for the context
- Now XPATH expressions or location paths are of two types :
- Relative path
- Absolute path
- Location Steps are the ones that make up an XPATH Expression. It consists of
- Axis
- Node name (context node name)
- Predicate (optional)
XPath uses a path expression to select node or a list of nodes from an XML document. Following is the list of useful paths and expression to select any node/ list of nodes from an XML document.
| Serial Number | Expression | Description |
|---|---|---|
| 1. | node-name | Select all nodes with the given name “nodename” |
| 2. | / (Forward Slash) | Selection starts from the root node |
| 3. | // | Selection starts from the current node that match the selection |
| 4. | . | Selects the current node |
| 5. | .. | Selects the parent of the current node |
| 6. | @ | Selects attributes |
| 7. | Item | Example – selects all the nodes with the name Item |
| 8. | Products/Item | Example - Selects all Item elements that are children of Products |
| 9. | //Item | Selects all the Item elements no matter where they are in the document |
| 10. | I | This is an operator for computing two sets of nodes |
Relative path consists of location step separated by “/”, while absolute path begins with “/” (referred as root node) followed by optional location steps.
For example : /child::catalog/child::book[1]/child::author is absolute path and child::book[1]/child::author is relative path.
child:: is axis [1] is predicate child::book[1] is a location step. catalog, book and author are node.
- Let’s start with Axes
- child axis contains the children of context node. For example : /child::catalog/child::book
- descendant axis contains the decendants or grandchildren of context node. For example : /child::catalog/descendant::author
- parent axis contains the parent of the context node, if there is one, For example : /child::catalog/child::book[1]/child::author/parent::*
- Ancestor axis contains the ancestors of the context node; the ancestors of the context node consist of the parent of context node and the parent’s parent and so on; thus, the ancestor axis will always include the root node, unless the context node is the root node. For example : /child::catalog/child::book[1]/child::author/ancestor::*
- following-sibling axis contains all the following siblings of the context node only if the context node is not an attribute node or namespace node. For example : /child::catalog/child::book[1]/child::author/following-sibling::*
- preceding-sibling axis contains all the preceding siblings of the context node only if the context node is not an attribute node or namespace node. For example : /child::catalog/child::book[1]/child::description/preceding-sibling::*
- attribute axis contains the attributes of the context node; the axis will be empty unless the context node is an element. For example : /child::catalog/child::book[2]/attribute::*
- namespace axis contains the namespace nodes of the context node; the axis will be empty unless the context node is an element. For example : /child::catalog/child::book[2]/namespace::*
- self axis contains just the context node itself
- descendant-or-self axis contains the context node and the descendants
- ancestor-or-self axis contains the context node and the ancestors of the context node; thus, the ancestor axis will always include the root node
- Some of the most popular abbreviations used in XPATH are :
- /catalog/book[1]/author/following-sibling::* instead of /child::catalog/child::book[1]/child::author/following-sibling::*
-
- instead of node().
- /catalog/book[2]/@id instead of /catalog/book[2]/attribute::id
- //author instead of /descendant-or-self::node()/child::author
Example to execute XPATH for an XML file
Scenario 1

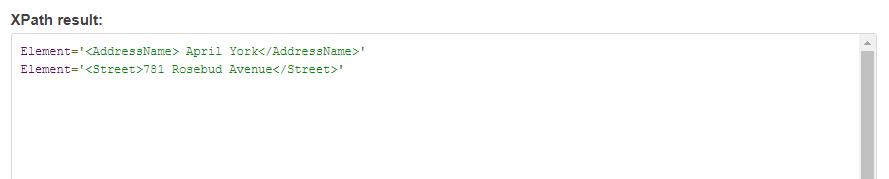
In the above XML provided, the node BPAddresses has multiple child nodes. To access the child Street & AddressName, the syntax for the XPATH should be :
XPATH Syntax :
BusinessPartners/BPAddresses/AddressName | BusinessPartners/BPAddresses/Street : The syntax accesses and displays the two element nodes,
simultaneously by computing two set of nodes.
XPATH Result Screen :
Scenario 2

In the above XML provided for this scenario, the parent node Bookstore, has multiple nodes with multiple elements with same node name.
- To access the elements of the book category = cooking, the syntax should be :
XPATH Syntax : /bookstore/book[1] - Selects the first book element that is the child of the bookstore element.
XPATH Result Screen :

- To access all the elements with the element name Author in the whole xml packet, the syntax should be :
Syntax : bookstore//book/author – Selects all the books node that is the child of the Bookstore element and fetches every element with the name “author” present in the xml packet.
XPATH Result Screen :