Merger Node
Updated:
What is Merger Node?
Merger Node integrates data documents into a single data packet, in order to avoid multiple hits to the application. The Merger Node combines multiple documents into a single document and pushes the combined file to the successive node as per the configuration in the merger node provided. This repeatation of the cycle continues until all data are merged and pushed.
Prerequisites: All input documents should have the same set of schema and attributes. Input document has to be in XML format
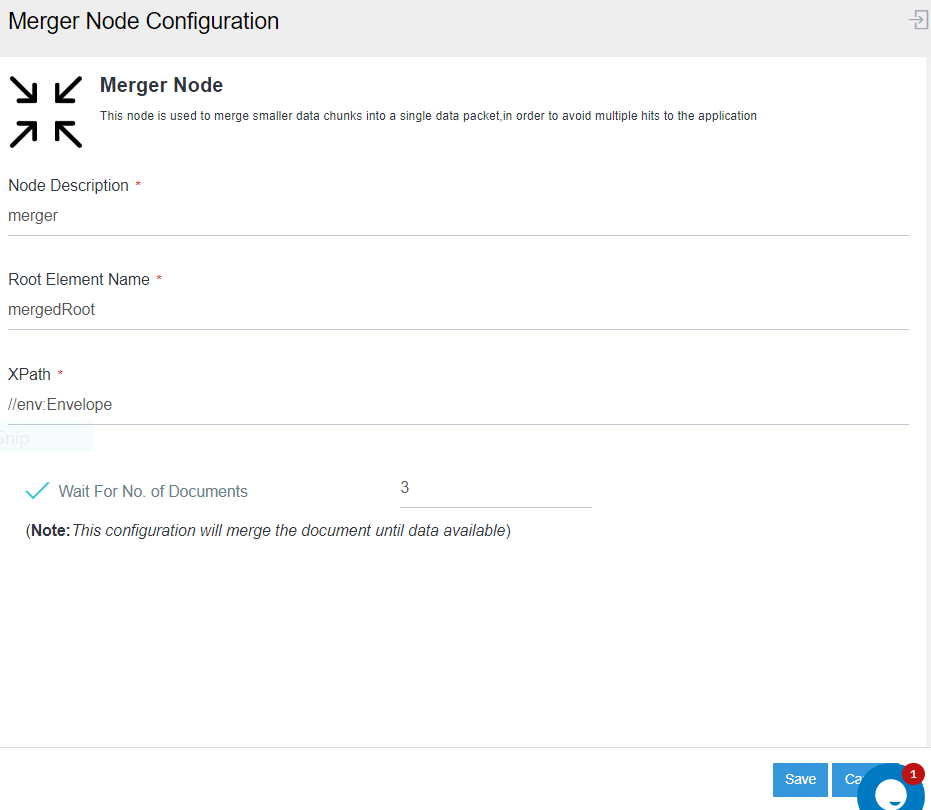
Like a SPLITTER node, Merger node also has Four Components Node - Node Description, Root Element Name, XPath and Wait for Documents.
Merger Node Input file - can have one or more document as input. Merger Node Output file - can have one or more document as output. However, it may depend on the configuration provided, and also on the incoming documents.
- Node Description : Here, you need to provide a description to the merger node.
- Root Element Name : Here specify the name which will act as a root element under which data will be merged.
- XPath : Here user need to specify a XPath based on which data will be fetched from each data file for merging.
- Wait for no. of documents : Here, you need to define the size of the batch as how many should be merged to form packets.
For example: You have eighteen records(Data) in EIGHTEEN different Documents where each incoming document contains ONE records.
The Wait for no. of documents in the Merger node configuration window is configured as TWO. Therefore, merger node will combine the first TWO incoming documents set into ONE and will post it to the successor node.
Merger node will again execute and will combine the next TWO sets and post as an another single document. The cycle will continue again and combine the next TWO set in the same way.
The below sheet will give you a graphical representation of the above described scenario.
Note: The Wait for no. of documents should not allow 0 as input and the range of batch size value
should be 1-999.
Working Principle
The concept of identifying the merger property is like that of the splitter property, that is by viewing the corresponding packet. However, it also depend on the position of the merger node. If the Merger node is placed after the Mapper Node, the XPATH should be as per the Transform packet,else if placed after GET or before Merger, the XPATH should be as per the Input packet. (In this case, it is the transform packet as the merger node is used after the Process node).
The XPath provided for the MERGER Node is shown below:
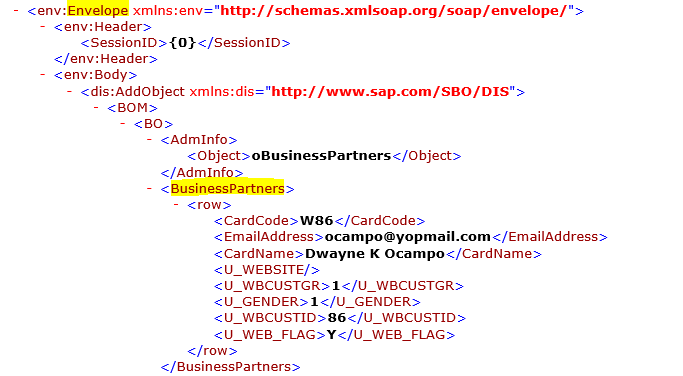
Application used for the Processflow Execution is: Magento2 and SAP B1.
1) Go to Processflow section & Design a Processflow.
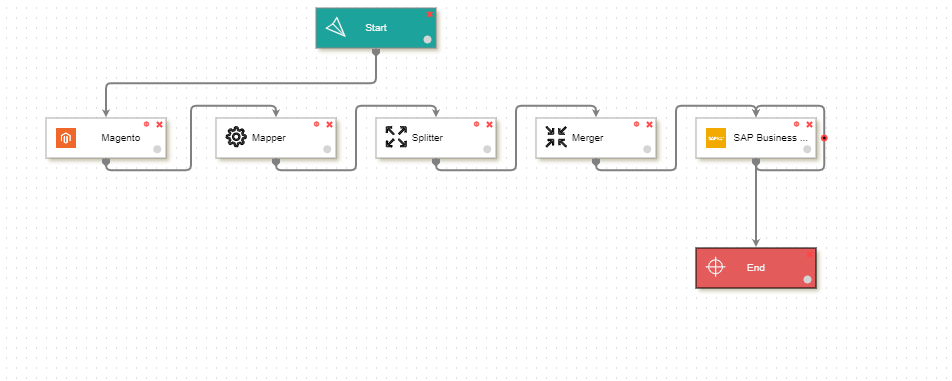
2) The Processflow is designed as shown in the above section of the screen. Here, splitter is added to split the records in single document to multiple documents.
3) You have to add Self loop in the destination node so that all the merged files are posted in the destination application, without any data loss.
4) Add the Merger node after mapper such that all the incoming files can be merged in a batch of 2.
5) Now Deploy the processflow. After successful deployment, to your environment, Execute the Processflow.
6) Go to Environment section of the portal, select the processflow from the listing section and click View Snapshot to view the detailed node by node snapshot data of the processflow.
7) Click on the Transaction files of splitter node to view the incoming files for merger node.
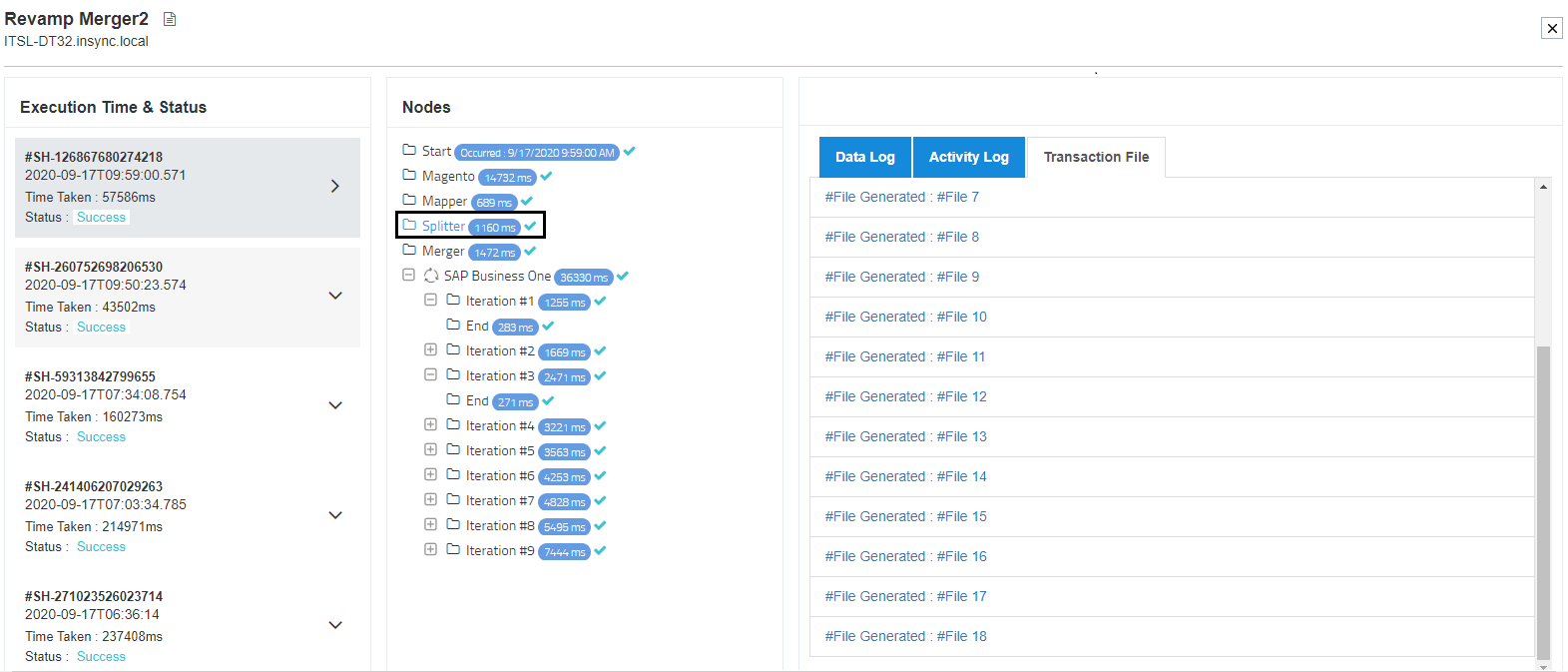
7) Click on the merger node to get the snapshot dataview of the merged files.
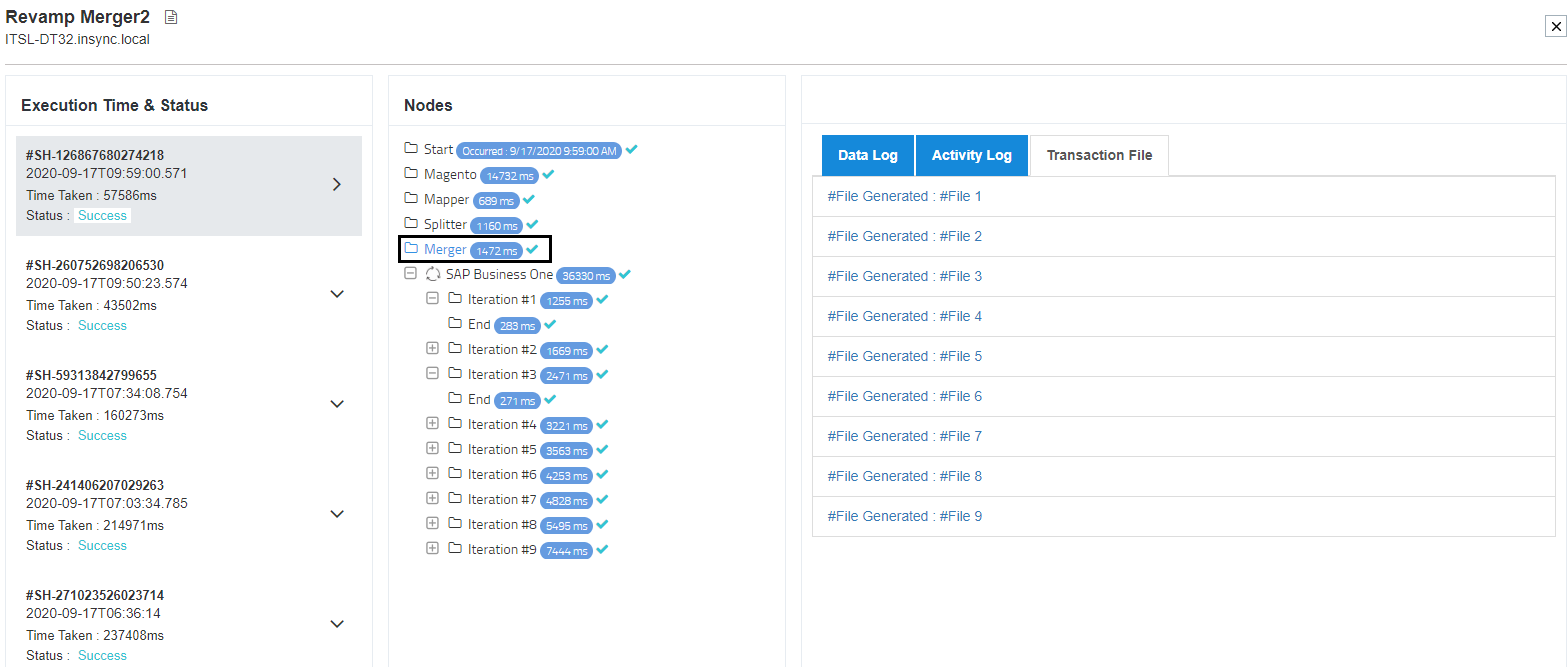
8) Now click on the Transaction File tab to view both the merged files for the merger node.
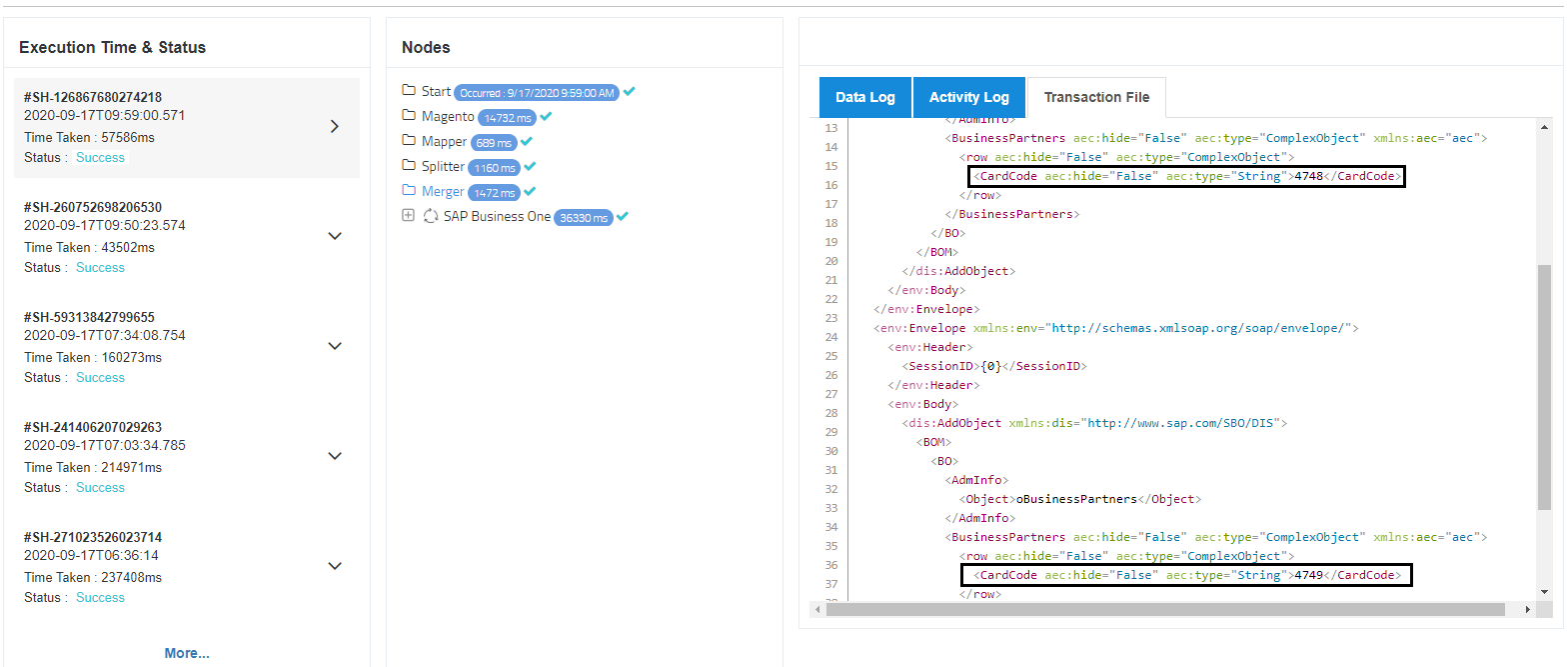
Here you can view TWO transactional files, containing two customer records in file ONE.
9) Expand the destination node to view the sync result of the iteration.
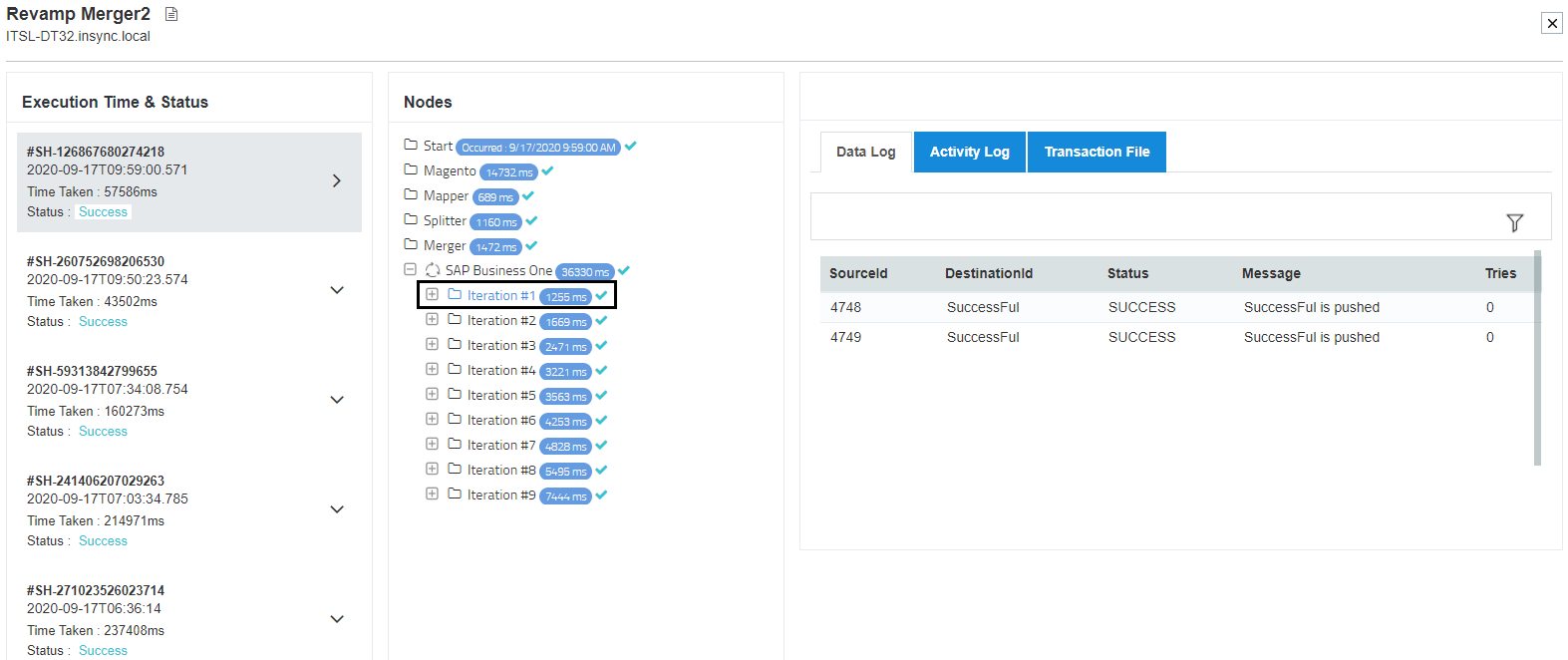 Here, the sync result is shown only for the iteration 1.
Here, the sync result is shown only for the iteration 1.
Thus, the above processflow is executed with the Merger node and you can also view the iteration wise node execution created with self loop.
Note: Since Self Loop configuration was set as Until Data Available, you will be generated with an extra iteration. For more details related to Self-Loop, Click Here.
1. Business Scenario - Applications with API request throttling
Throttles indicate a temporary state, and are used to control the data that clients can access through an API. When a throttle is triggered, you can disconnect a user or just reduce the response rate. There are certain applications (e.g. amazon, shipstation etc.) with the problem of API Request throttling. These applications generates throttling after a certain point of time, hence it becomes cumbersome to sync data continously through these API’s.
Here merger node can be implemented before destination application where the multiple files can be merged into one or more data packets to override the API throttling issues of destination applications.
Here you need to add the merger node after mapper node and before destination application node, using a self loof (to combat data loss). The splitted data packets will be now be easily posted to the destination application for the respective data packets without API throttling.