One-Way Sync Strategy
Updated:
In most cases of application integration, you might opt for an e-way sync strategy only, it is best to understand what approach
you should take when you create the integration. Applications are different in terms of architecture or even in terms of their APIs or
data formats. Depending on the availability and capabilities of an API and the configurability of the application itself we choose one
that is suitable for your business case. However if you do have a choice, use the recommendations below to identify the best
strategy for your situation.
For one-way sync we consider 3 scenarios :
- Record Flag and Validate
- Remember Last Modified Time
- Capture Data
Record Flag and Validate
In this approach, records are extracted from the source application based on the value of some status or Flag value.
Upon completion of successful record sync to the destination application, we consider updating the flag on the source application
again so as to ensure that the synchronization does not re-capture the same data again. This strategy provides a lot of flexibility
and end users can easily control the sync behavior by modifying values within the end application.
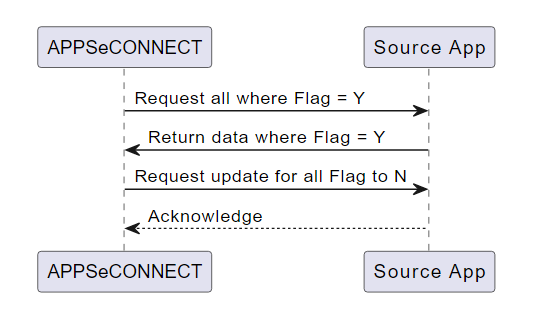
The flag field can take on different forms and will depend on the application. It could be an actual
status field (integration-specific or business-related), field containing true or false value,
the existence of an external ID etc. It could also be a combination of fields and values.
We consider updating this field just after the record is successfully captured. We might want to consider the
default value of a particular data object to be as Not synced or might also want to consider to define the
initialization value. You could also consider updating the status of the flag when there is any change made to
the source data again. Hence, if you try to follow this approach, you might need to develop some kind of logic
around the application so as to ensure the application works correctly as expected.
Pros and Cons
- In this approach the integration allows the record to be synched without much data dependency. Such that if one part of a record is synched and others in the group fail, the integration can still partially work.
- If the flag field is exposed to the user through the user interface, the user can also trigger sync just by updating the record.
- The integration remains stateless.
- Requires source application to be updated, and hence you cannot execute the same process parallelly.
- If the source application does not support field-level customizations or expose the field from the layer, you might not find this approach as an option.
Remember Last Modified Time
If you donot have an option to create or alter the field in the application, you should consider the timestamp to
capture the data change. In this approach, the data is captured using the Last update date. The process records the most recent entries
and stores it in persistent storage such that the filters execute again based on the time saved. Generally, this
approach is best suited when the API provides a filter criterion for record retrieval and storing the time from
the retrieved data eliminates any calculation regarding the server time differences.
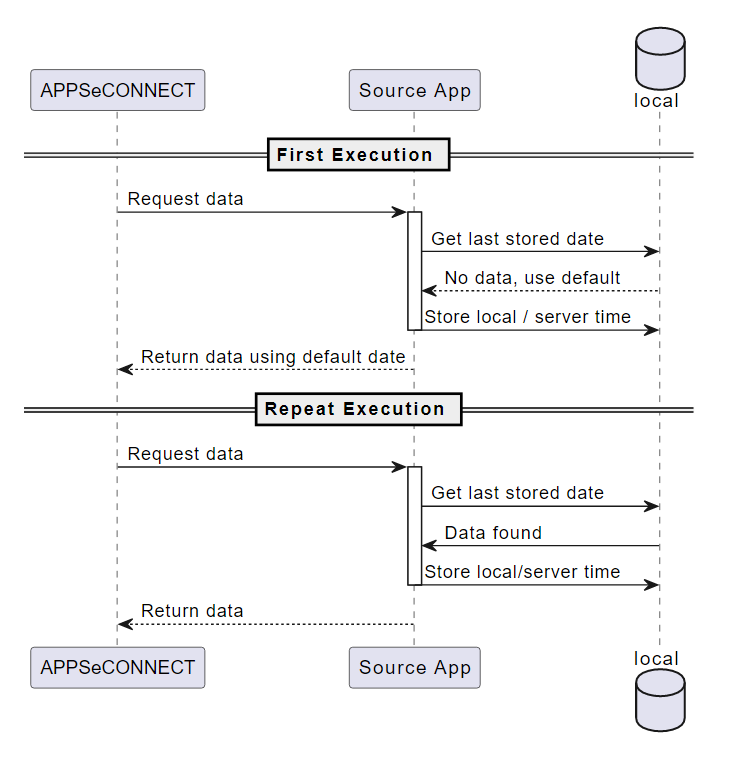
This approach captures the timestamp to ensure the integration works best without major duplicate values. You can even choose the current system time or your server time or even store the current time in GMT, but if there is an option to choose the time from the retrieved record, the data should not be missed out. In this approach, the most critical thing is to handle the errored resync data.
Pros and Cons
- This is a much simpler integration design because there is no extra step to update something to the source but this approach makes integration
statefulwhich is sometimes troublesome when you want to load balance integration agents. - There is no need to do application end customizations. But as there is persistent storage involved, the data persisted within the integration platform that needs to be backed up considerably and needed to be retrieved back during disaster recovery.
- This process does not work best if your application does not provide filter based on date and time in terms of milliseconds and also it does not work when there are data imports on the application which results in the generation of the same DateTime in multiple records.
- The process sometimes gets complex when there are multiple parameters involved, like pagination, sort criteria, etc.
Capture Data
In case your API does not expose DateTime or you do not have an option to update flag field on each record,
only option that you have in such scenario is to record some kind of checksum or hash for each record on the
integration platform to ensure the duplicate checks could be easily identified even though duplicate data
is retrieved each time. In addition to store the unique hash generated on the record, it is also important
to store the record id, such that one can easily identify data modifications.
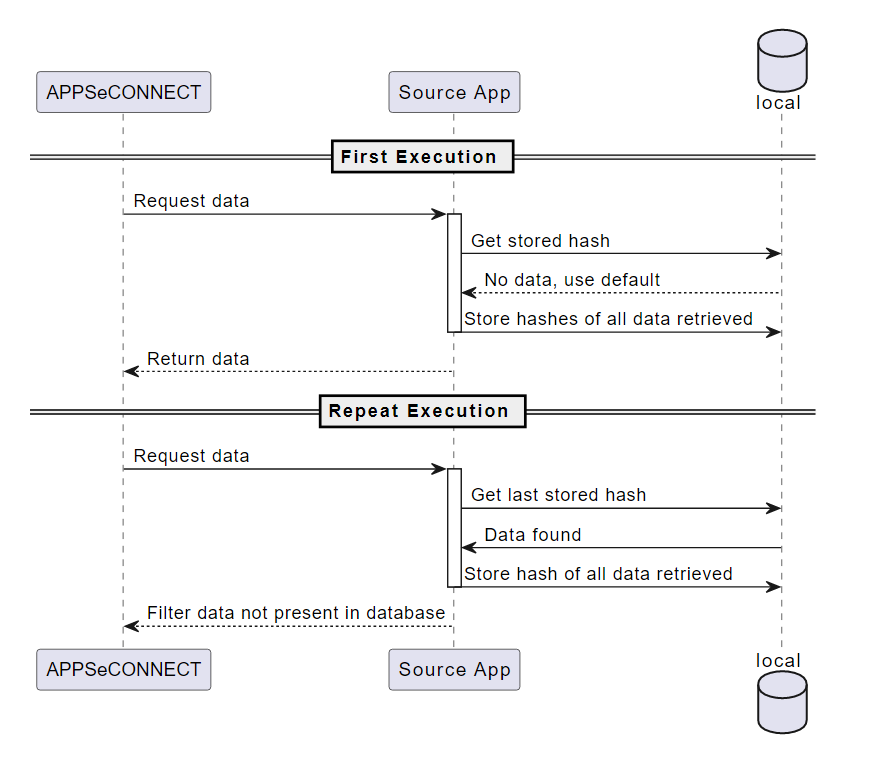
Generally, this is a rare scenario in modern-day applications, but for legacy application when there is file system or FTP based integration involved or in case of stock or product catalog updates, you might go with this scenario. This approach is suitable mostly for master data, and should not be used for transactional records.
Pros and Cons
- The most important pros for this approach are that there is no integration step involved to do such a step.
- The integration platform can provide a generalized option to handle this type of integration.
- This approach becomes very stateful and might sometimes require the entire record needs to be stored in the integration platform.
- With growing data size, the checking of each record can be cumbersome and time-consuming.