Splitter Node
Updated:
What is Splitter Node?
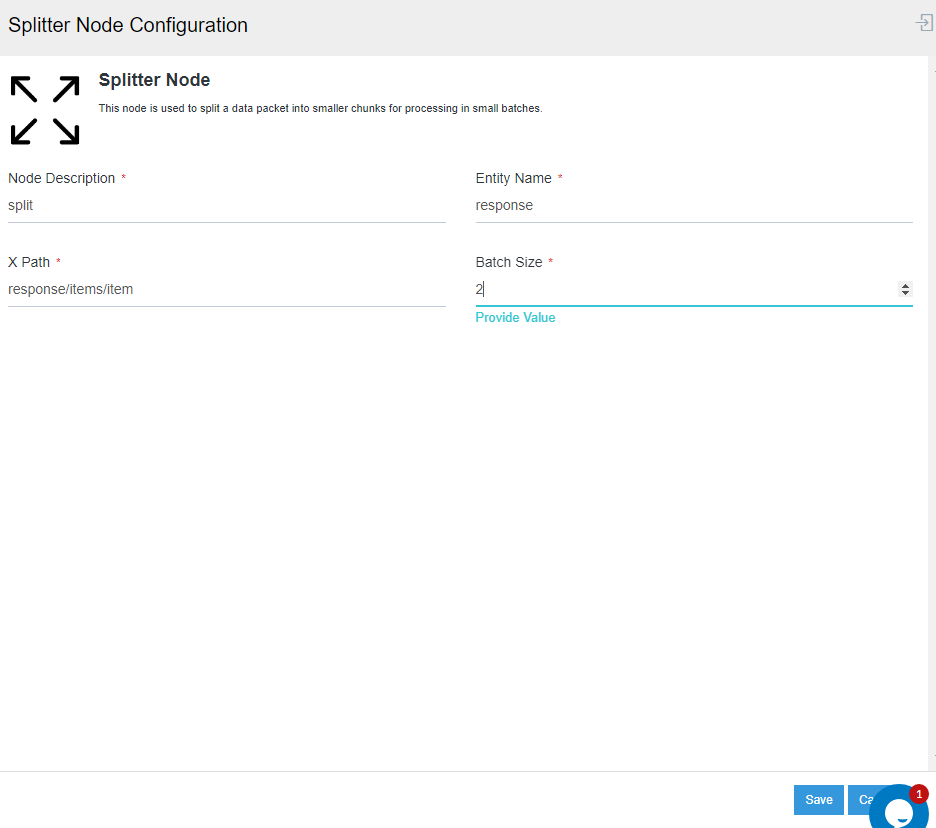
This node is used to split a data packet into smaller chunks for processing in small batches. There are four components in a splitter node of a processflow as shown below.
- Node Description : Here, you can provide a short description for the splitter node.
- Entity Name : Here you can specify the name which will act as a root element to append the splitted data.
- XPath : Here user need to specify a XPath based on which data will be splitted.
-
Batch Size : Here you need to specify the number of data to be present in each splitted data of the output file of the spiltter node.
For example, suppose you have a data packet which contains 10 customer data and you applied a splitter with 2 batch size, so after execution of the splitter node the data packet will be split into 5 data packets where each packet contains two customer data and smaller packets will be sent to the next node for processing.
Note :
(a)Entity Name should be the same as in the Input Document.
(b)The wrong Xpath given by the user will throw an error during execution.
(c)Batch Size 0 will not be allowed.
Working Principle
SPLITTER node in APPSeCONNECT processflow is used for splitting large volume of data received as input files and
breaking them into smaller chunks go to the next process of transformation in the processflow. For example, let an input packet contains 20 customer data. A batch size of 1 is defined in the splitter node,where XPATH is response/items/item and Entity name as response.
So, after data passed through the splitter node 20 individual XML data files will be created as output file where each file contains a single customer data.
For providing the properties of Splitter/ Merger, XPath for the packets is needed to be known.
The Parent node for the items present in the XSLT is the XPATH that needs to be given in the Splitter and Merger Property.
Note : Single forward Slash (For Eg: /Items) access all the sub nodes present inside it. Double Forward Slash (For Eg: //Items) access all the nodes present inside it.
The XPath provided in the splitter node section also depends on the packets. If the Splitter Node is attached before the mapper node the Xpath needs to provided viewing the INPUT Packet and if the spliter node is attached after the mapper node the XPath is needed to be provided viewing the Transform Packet.
The Entity field is the Parent nodes of the packet that would be split. The XPath are the child nodes of the Entity.
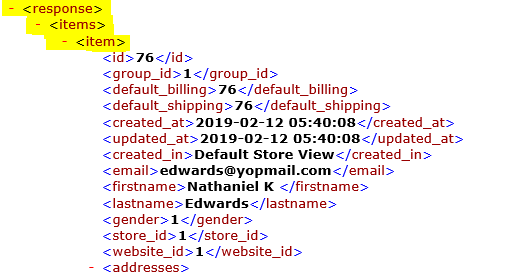
Application used for the Processflow Execution is: Magento2 and SAP B1.
The XPath provided for the node SPLITTER (Magento2 to SAP B1) is shown above :
1) Go to Processflow section & Design a Processflow.
2) The Processflow is designed as shown in the screen below.
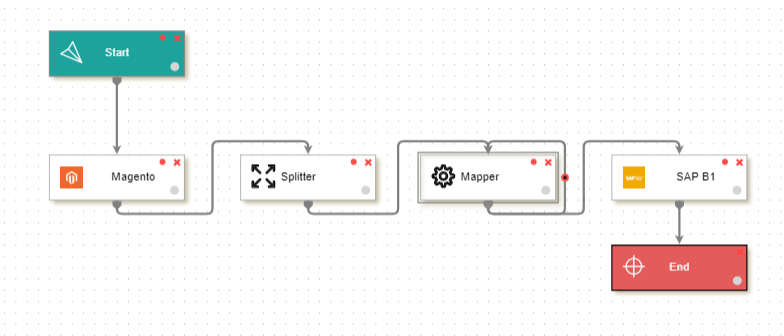 3) Here the
3) Here the splitter node is used after getting customer data from Magento,
and splitting it into multiple output packets for posting in destination application.
4) You have to add Self loop in the mapper node so that all the splitted files are executed
and posted in the destination application, to avoid any data loss.
5) Now Deploy the processflow. After successful deployment, to your environment, Execute the Processflow.
6) Go to Environmentsection of the portal, select the processflow from the listing section and click View Snapshot
to view the detailed node by node snapshot data of the processflow.
7) Click on the Splitter node to get the snapshot dataview of the splitted files.
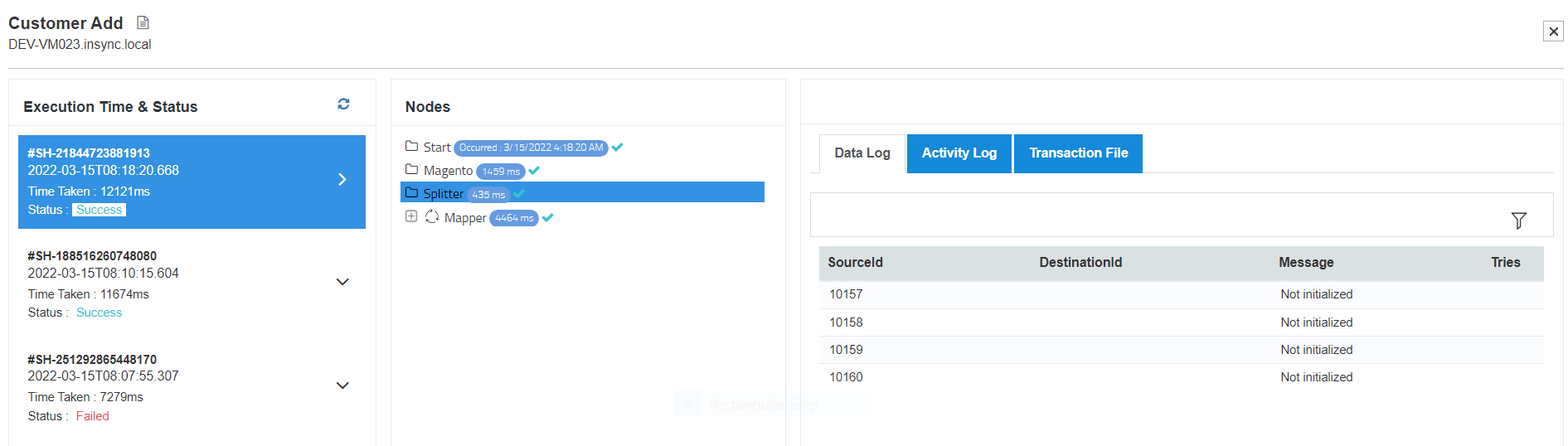
8) Now click on the Transactional Log to view the splitted data.
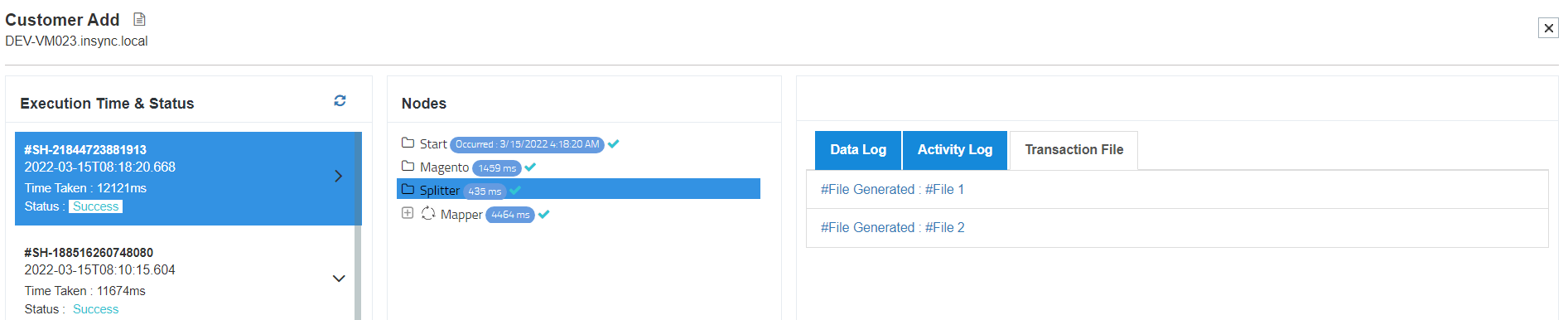
Here you can view two splitted files are created each containing two customer record for further processing and
posting in destination application.
9) Now Click on Mapper node and you can view two iterations are created for two files
which are processed. Every Iteration has - Data Log, Activity Files & Transactional Files where you can view
the file details.
10) Click on the destination application node present under every iteration to view the
file posting status - Success/Failure.
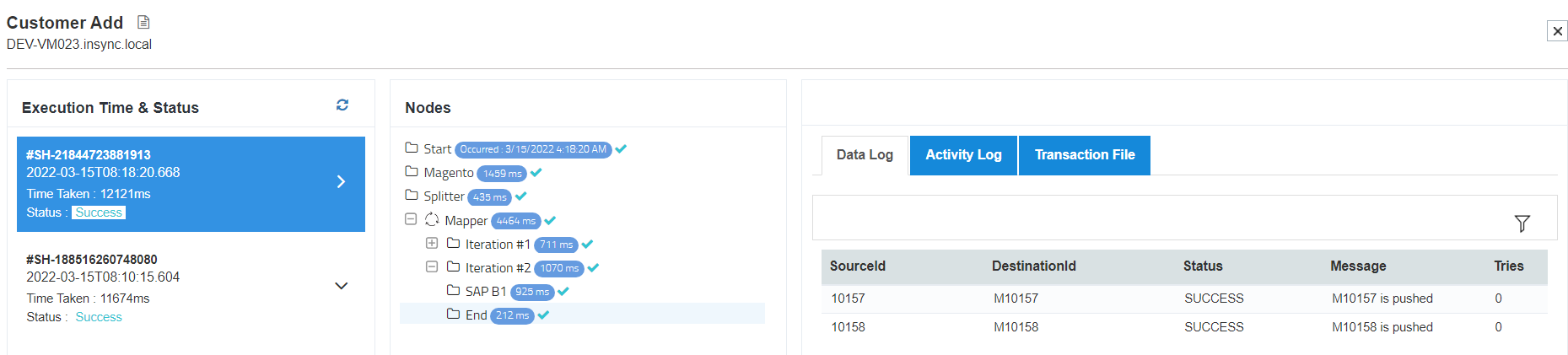
Note: Since Self Loop configuration was set as Until Data Available, you will be generated with an extra iteration. For more details related to Self-Loop, Click Here.
Thus, the above processflow is executed with the splitter node and you can also view the iteration wise node execution created with self loop.
Business Scenario - Low Server Response in Destination Application
- Here you design a processflow with splitter node. The splitter node is attached after Source Application (E.g: Magento2) which is fetching a huge number of data but the destination application (E.g: SAP B1) is unable to sync the single data packet with huge number of data due to low server response.
- We are adding the splitter node after the source application and defining a batch size in splitter node window for data packet generation in smaller chunks.
- Now Self loop is added to the mapper node, which enables to run the execution until all data are available from the source application, and it enables to stop any data loss due to splitter node.
- The data packets are thus transformed and posted in multiple output packets in destination application, thereby enabling a smooth sync process of huge data into splitted data packeets with low server response capability.
Protip: The ENTITY and the XPATH is different for the INPUT Packet, TRANSFORM Packet, OUTPUT Packet and for different Application.